
Yorris Siagian
Machine Learning Engineer | AI Enthusiast
💼 Tentang Saya
Saya adalah lulusan Teknik Informatika dari Universitas Medan Area. Saya memiliki minat yang besar dalam membangun sistem AI dan Machine Learning dari awal hingga tahap implementasi. Fokus saya meliputi pemahaman data, pembuatan model, deployment, hingga monitoring performa model di lingkungan produksi.
🧰 Tools Favorit
- Python
- scikit-learn
- TensorFlow
- Streamlit
- MLflow
- Metabase
- Prometheus
- Docker
👨💼 Pengalaman Kerja
- Web Administrator – Tobacamp (Juli 2023 - September 2024)
Bekerja dalam Bertanggung jawab atas pengelolaan website mulai dari pemeliharaan hingga konten website dan bertanggung jawab sebagai mentor UX Design untuk pelatihan UX Design.
🎓 Riwayat Pendidikan
- Universitas Medan Area – S1 Teknik Informatika (2019–2024)
🚀 Proyek Saya
🌾 Deteksi Penyakit Tanaman PertanianDeteksi Penyakit Tanaman
🔗 Lihat Proyek Lengkap di GitHub
Sistem klasifikasi 31 kelas daun tanaman (sehat dan sakit) berbasis MobileNetV1, di-deploy via Streamlit.
Peran: Lead tim, tuning model, deployment.
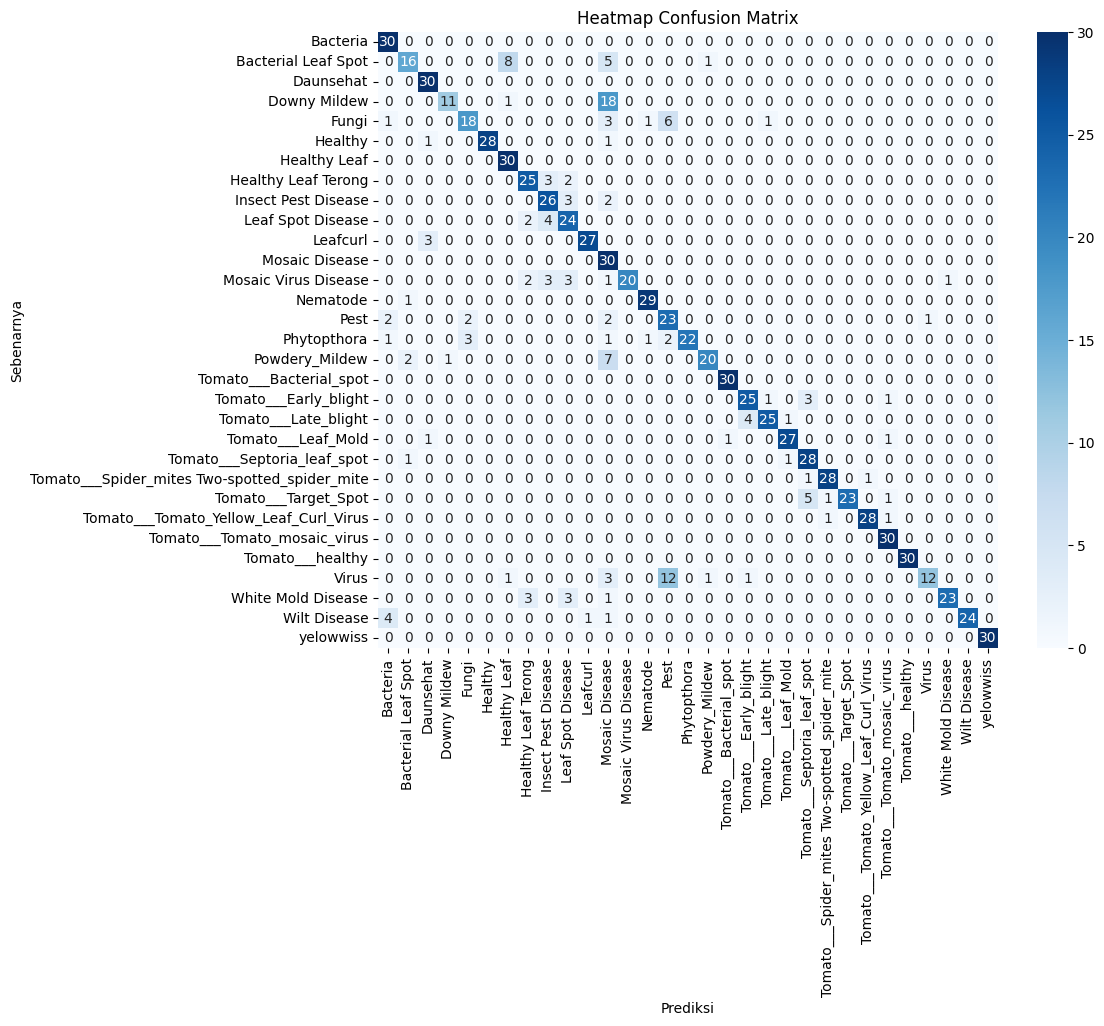
Confusion matrix 31 kelas daun, akurasi & F1-score 82%. Beberapa kelas mirip masih tertukar.
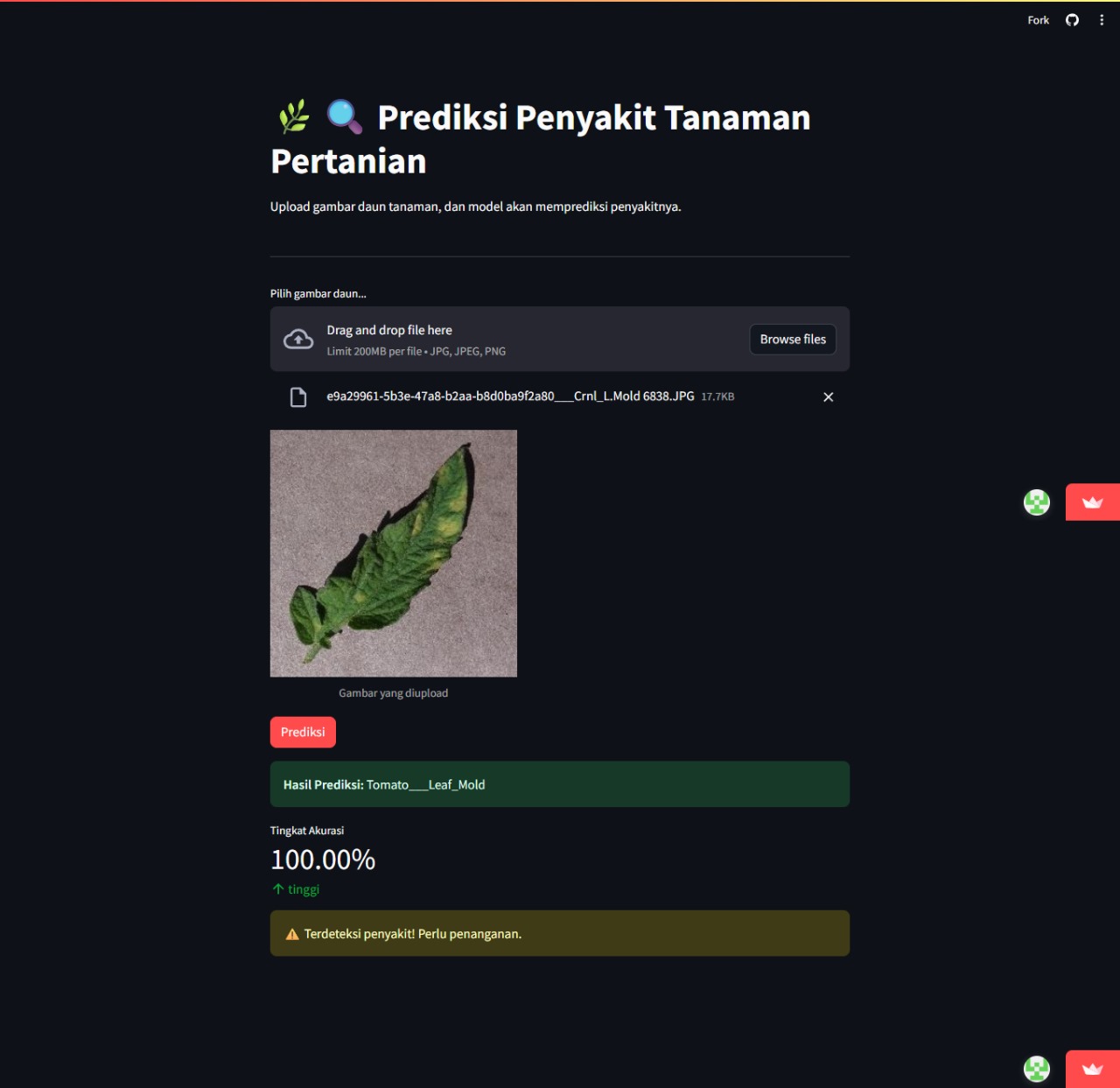
Tampilan aplikasi Streamlit: upload gambar daun, hasil klasifikasi muncul langsung.
Image Classification MobileNetV1 Streamlit Transfer LearningAgritech
Prediksi Dropout Mahasiswa
🔗 Lihat Proyek Lengkap di GitHub
Prediksi risiko dropout menggunakan Random Forest, dashboard Metabase, dan aplikasi Streamlit.
📊 Dashboard
Visualisasi distribusi dropout berdasar gender, usia, beasiswa, dan ekonomi.
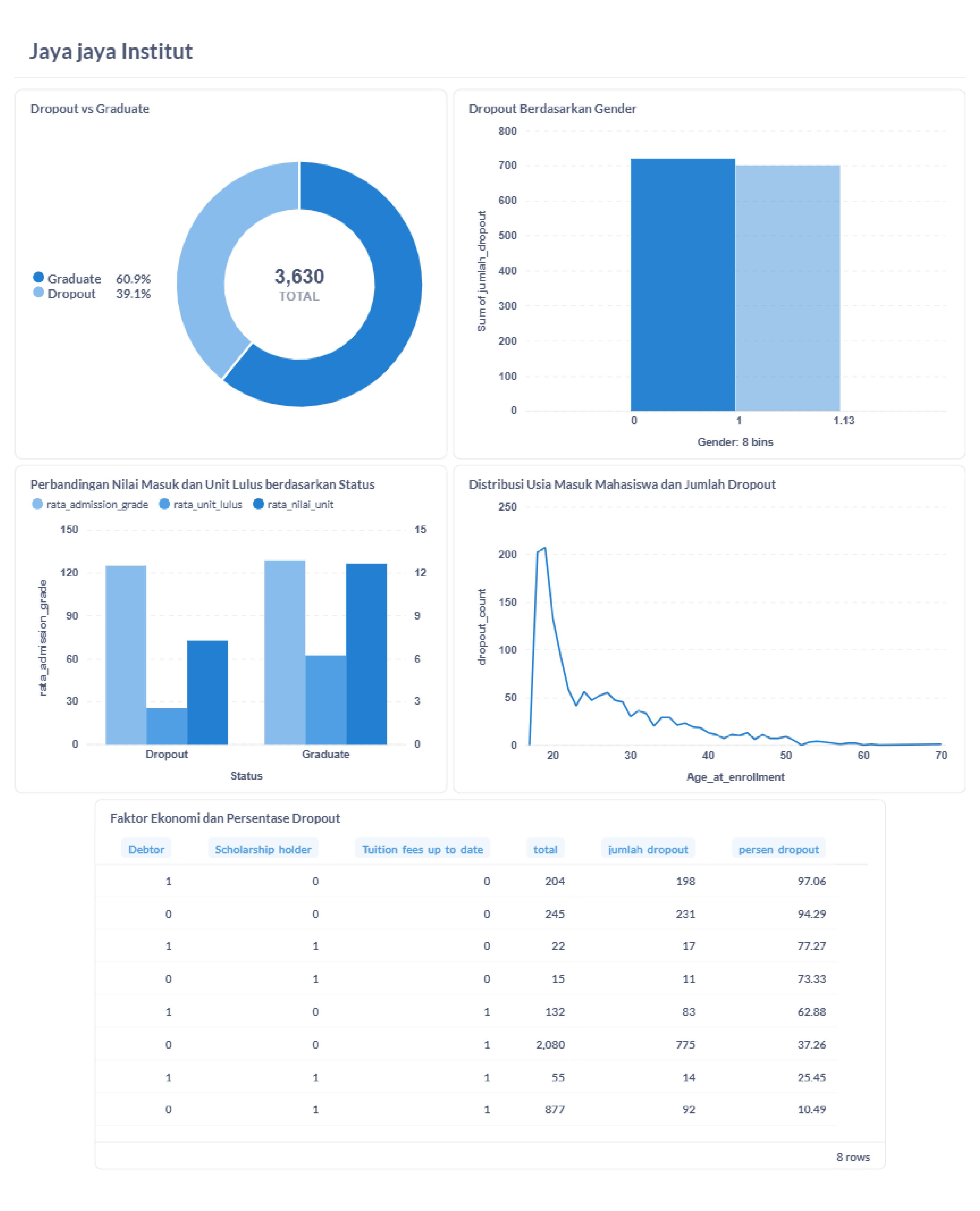
Dashboard Metabase menampilkan insight penting terkait dropout.
🧠 Prediksi Model
- Akurasi: 91.87%
- F1-score dropout: 0.89
Fitur penting: tunggakan, beasiswa, usia masuk, nilai masuk.
🖥 Aplikasi Streamlit
Form input mahasiswa untuk prediksi dropout secara langsung.
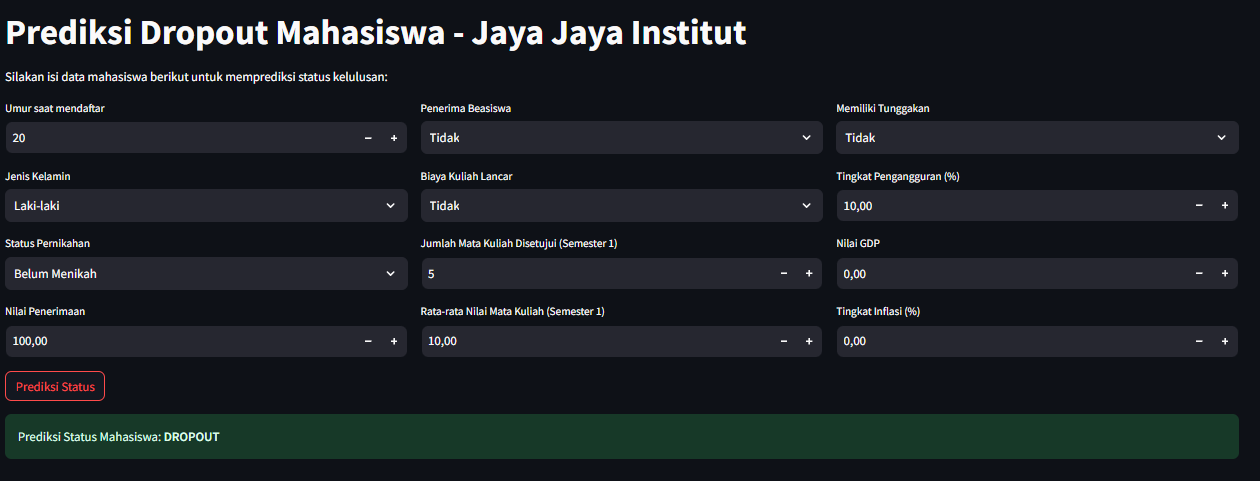
Form interaktif prediksi status mahasiswa berdasarkan input data.
🔗 Lihat Demo Aplikasi Streamlit
Classification Metabase Streamlit Random Forest
Attrition Analysis - Jaya Jaya Maju
🔗 Lihat Proyek Lengkap di GitHub
Proyek akhir Belajar Penerapan Data Science oleh Laskar AI x Dicoding menganalisis attrition (>12%) di Jaya Jaya Maju menggunakan Logistic Regression dan dashboard Metabase.
Analisis fokus pada lembur, promosi, dan masa kerja. Model seimbang dipilih karena meningkatkan recall dari 50% ke 72%. Visualisasi menampilkan attrition per departemen, dampak lembur, dan tren promosi.
Insight utama: lembur dan minimnya promosi dalam 0–2 tahun jadi pemicu attrition. Departemen Sales menyumbang attrition tertinggi (~22%). Direkomendasikan pengurangan lembur dan promosi terjadwal.
Model Disimpan: logistic_attrition_model.pkl (class-balanced version)
Visualisasi Dashboard Metabase:
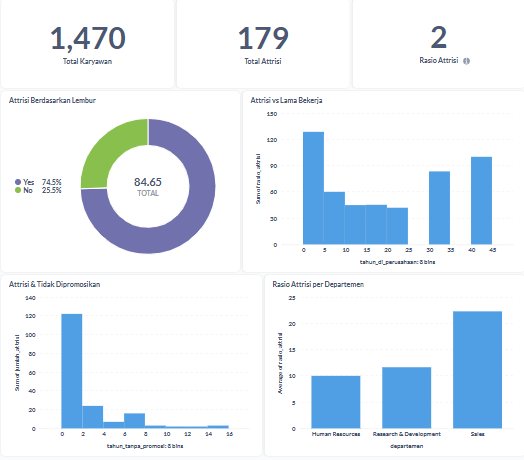
Visual ini menampilkan ringkasan attrition rate perusahaan, distribusi berdasarkan lembur, masa kerja, promosi terakhir, dan departemen. Tujuannya adalah memberi wawasan cepat dan actionable kepada tim HR melalui tampilan interaktif berbasis Metabase.
HR Analytics Logistic Regression Metabase
Klasifikasi Daun Tomat Menggunakan CNN
🔗 Lihat Proyek Lengkap di GitHub
Proyek akhir kelas Belajar Fundamental Deep Learning ini menggunakan CNN untuk klasifikasi 10 penyakit daun tomat dari 10.000 gambar, dengan augmentasi untuk generalisasi.
Arsitektur terdiri dari 3 blok Conv2D + MaxPooling, dilanjutkan Dense dan Dropout. Model dilatih dengan Adam optimizer dan EarlyStopping.
- Akurasi: 91.2%
- F1-Score Macro: 0.91
- Performa stabil di semua kelas, termasuk daun sehat
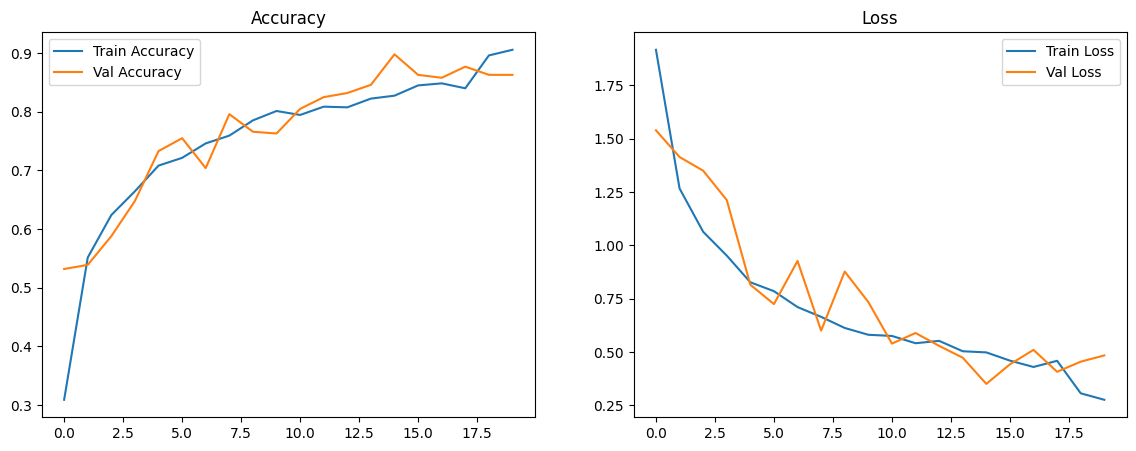
Learning Curve: Menunjukkan bahwa model tidak overfitting dan berhasil belajar dari data secara konsisten.
CNN Image Classification Tomato Disease Deep Learning
Klasifikasi Wajah Anak Autis Menggunakan SURF dan Boosting
🔗 Lihat Proyek Lengkap di GitHub
Proyek skripsi ini mengembangkan sistem klasifikasi wajah anak dengan dan tanpa autisme menggunakan fitur SURF dan lima algoritma Boosting.
🎯 Tujuan
- Mengklasifikasikan wajah anak autis dan normal berbasis citra.
- Mengevaluasi performa lima model Boosting terhadap fitur hasil ekstraksi SURF.
📁 Dataset
Terdiri dari 203 gambar (102 autis, 101 normal) dari Bundaku Autism Clinic Center, dengan split data 80% pelatihan dan 20% pengujian.
⚙️ Metodologi
Gambar diubah ke grayscale, fitur diekstraksi menggunakan SURF, lalu diklasifikasikan dengan AdaBoost, GradientBoost, LightGBM, CatBoost, dan XGBoost. Evaluasi menggunakan metrik Accuracy, Precision, Recall, F1, dan F2-Score.
📊 Hasil Evaluasi
| Algoritma | Akurasi | Precision | Recall | F1-Score | F2-Score |
|---|---|---|---|---|---|
| AdaBoost | 68.29% | 69.49% | 69.02% | 68.22% | 68.45% |
| Gradient Boosting | 73.17% | 73.57% | 73.57% | 73.17% | 73.31% |
| LightGBM | 73.17% | 73.10% | 73.21% | 73.11% | 73.16% |
| CatBoost | 80.49% | 80.60% | 80.74% | 80.74% | 80.59% |
| XGBoost | 70.73% | 70.84% | 70.93% | 70.72% | 70.80% |
📌 Kesimpulan
Proyek ini membuktikan bahwa kombinasi SURF + Boosting efektif membedakan wajah anak autis dan normal. CatBoost menjadi model terbaik dengan F1 dan F2-score di atas 80%. Hasil ini membuka peluang pengembangan sistem diagnosis dini berbasis wajah.
SURF Boosting Autism Detection Machine Learning
Analisis Sentimen
🔗 Lihat Proyek Lengkap di GitHub
Proyek kelas "Belajar Fundamental Deep Learning" menganalisis sentimen 10.000 review Gojek dari Google Play Store. Tahapan mencakup scraping, preprocessing, pelabelan berbasis lexicon, visualisasi, dan klasifikasi dengan MLPClassifier.
Proses mencakup slang correction, tokenisasi, stopword removal, dan stemming. Sentimen ditentukan via lexicon, dengan model MLPClassifier mencapai akurasi 92,14%.
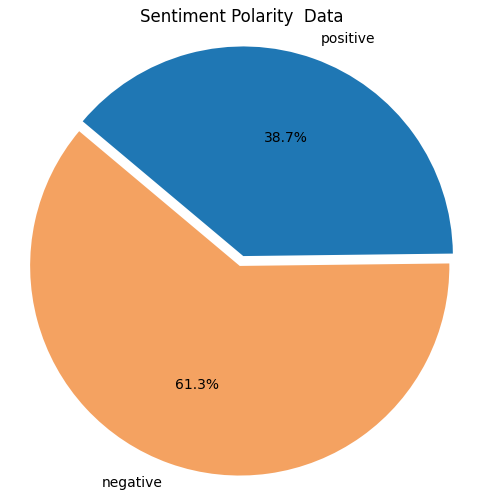
Distribusi Sentimen: Pie chart menunjukkan mayoritas review bernada positif, diikuti proporsi signifikan review negatif, yang menjadi dasar evaluasi performa model klasifikasi.

WordCloud: Visualisasi kata-kata yang paling sering muncul dalam review pengguna aplikasi Gojek. Kata "gojek", "driver", dan "layanan" termasuk yang paling dominan.
📈 Evaluasi Model Klasifikasi (MLPClassifier)
- Akurasi Training: 98.11%
- Akurasi Testing: 92.14%
Classification Report (Testing - MLP):
precision recall f1-score support
0 0.93 0.94 0.94 3966
1 0.90 0.89 0.90 2471
accuracy 0.92 6437
macro avg 0.92 0.92 0.92 6437
weighted avg 0.92 0.92 0.92 6437
📌 Hasil & Insight
Dataset review Gojek diproses dengan pipeline teks dan labeling lexicon. WordCloud mengungkap kata kunci pengguna, sementara MLPClassifier mencapai akurasi tinggi, menunjukkan pendekatan sederhana bisa menghasilkan model NLP yang efektif dan andal.
NLP Sentiment Analysis Lexicon-Based MLPClassifier
Membangun Proyek Machine Learning
🔗 Lihat Proyek Lengkap di GitHub
Submission akhir kelas "Membangun Proyek Machine Learning" yang terdiri dari dua bagian: Clustering pengeluaran masyarakat & Klasifikasi berdasarkan hasil klaster.
🔷 Clustering: Segmentasi Masyarakat Berdasarkan Pengeluaran
Menggunakan KMeans (3 klaster) dengan PowerTransformer, jumlah klaster dievaluasi via Inertia dan Silhouette Score. Analisis distribusi pengeluaran dilakukan untuk mengidentifikasi skewness dan outlier, lalu masyarakat disegmentasi berdasarkan pola pengeluaran tahunan.
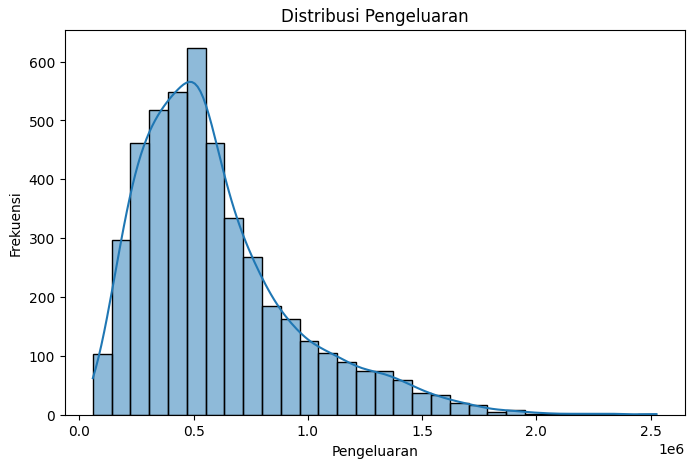
Distribusi Pengeluaran: Histogram menunjukkan mayoritas masyarakat berpengeluaran rendah dengan outlier signifikan, sehingga diperlukan transformasi data sebelum clustering.
.png)
Evaluasi Jumlah Cluster: Metode Elbow dan Silhouette Score digunakan untuk menentukan jumlah klaster optimal. Hasil menunjukkan bahwa 3 klaster memberikan pemisahan terbaik antar segmen masyarakat.
🔶 Klasifikasi: Prediksi Segmentasi Masyarakat
Menggunakan model Logistic Regression dan KNN, evaluasi menunjukkan akurasi dan F1-score >99%. Hyperparameter tuning dilakukan dengan GridSearchCV dan RandomizedSearchCV, disertai visualisasi confusion matrix dan learning curve untuk analisis performa.
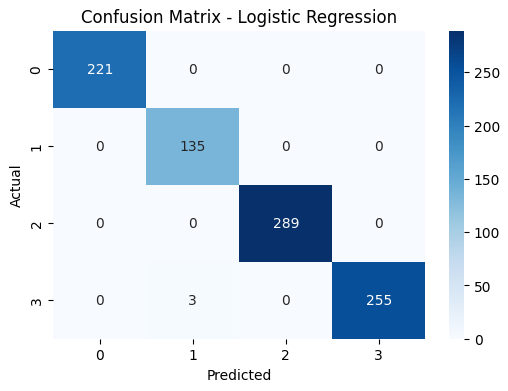
Confusion Matrix (Logistic Regression): Model berhasil mengklasifikasikan setiap kelas dengan sangat akurat, hampir tanpa kesalahan.
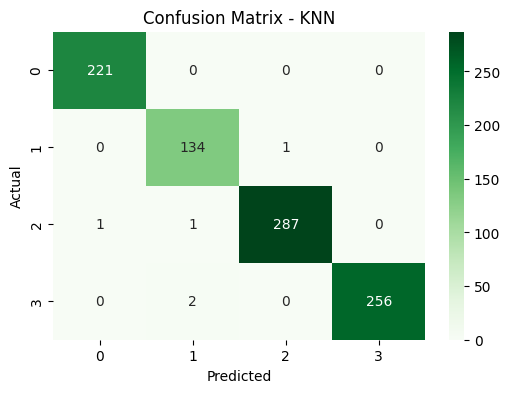
Confusion Matrix (KNN): Performa tinggi secara umum, meski sedikit lebih rendah pada kelas minoritas dibanding Logistic Regression.
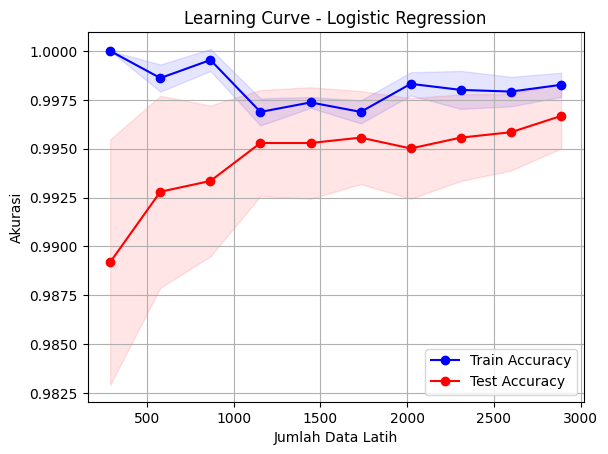
Learning Curve (Logistic Regression): Kurva training dan validation yang mendekat menunjukkan model general dan tidak overfit.
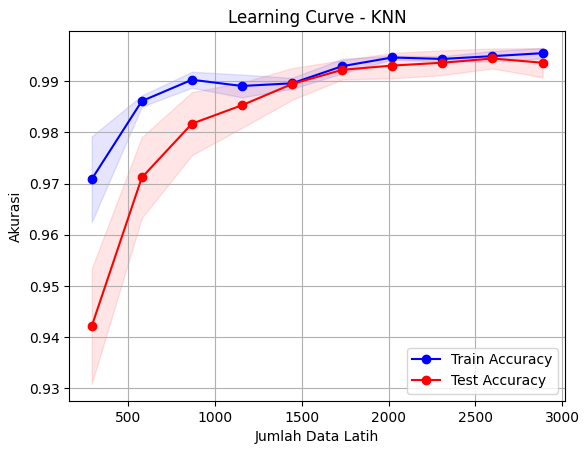
Learning Curve (KNN): Kinerja stabil dengan sedikit variasi, menunjukkan model cukup fleksibel terhadap perubahan data.
📌 Hasil & Kesimpulan
Proyek ini menerapkan KMeans untuk segmentasi pengeluaran tahunan, dengan PowerTransformer untuk normalisasi data skewed. Tiga klaster terbukti optimal.
Klaster digunakan sebagai label klasifikasi. Model Logistic Regression dan KNN mencapai F1-score >99% dengan confusion matrix nyaris sempurna.
Learning curve menunjukkan performa stabil tanpa overfitting, menandakan pipeline yang efektif dan andal.
MLOps Clustering Classification Tuning
📣 Kontak Saya
- Email: yorrissiagian@gmail.com
- LinkedIn: linkedin.com/in/yorrissiagian
- GitHub: github.com/Yorrissiagian